In this Lab, we will discover how we can develop LSTM recurrent neural network models for sequence classification problems in Python using the Keras deep learning library.
Recurrent neural networks (RNN):-
Recurrent neural networks have a wide array of applications. These include time series analysis, document classification, speech and voice recognition. In contrast to feedforward artificial neural networks, the predictions made by recurrent neural networks are dependent on previous predictions.
To elaborate, imagine we decided to follow an exercise routine where, every day, we alternate between lifting weights, swimming and yoga. We could then build a recurrent neural network to predict today’s workout given what we did yesterday.
Long short-term memory:-
LSTM is an artificial recurrent neural network (RNN) architecture used in the field of deep learning (DL). Unlike standard feedforward neural networks, LSTM has feedback connections. It can process not only single data points (such as images), but also entire sequences of data (such as speech or video). For example, LSTM is applicable to tasks such as unsegmented, connected handwriting recognition,speech recognition and anomaly detection in network traffic or IDSs (intrusion detection systems).
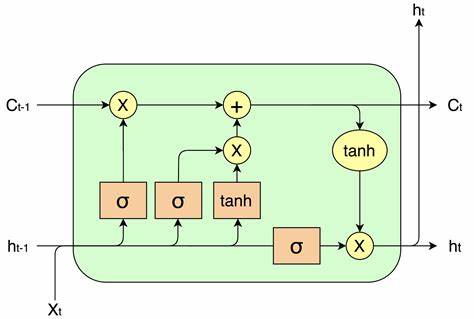
A common LSTM unit is composed of a cell, an input gate, an output gate and a forget gate. The cell remembers values over arbitrary time intervals and the three gates regulate the flow of information into and out of the cell.
LSTM networks are well-suited to classifying, processing and making predictions based on time series data, since there can be lags of unknown duration between important events in a time series. LSTMs were developed to deal with the vanishing gradient problem that can be encountered when training traditional RNNs. Relative insensitivity to gap length is an advantage of LSTM over RNNs, hidden Markov models and other sequence learning methods in numerous applications.
Word Embedding:-
We will map each movie review into a real vector domain, a popular technique when working with text called word embedding. This is a technique where words are encoded as real-valued vectors in a high dimensional space, where the similarity between words in terms of meaning translates to closeness in the vector space.
Keras provides a convenient way to convert positive integer representations of words into a word embedding by an Embedding layer.
We will map each word onto a 32 length real valued vector. We will also limit the total number of words that we are interested in modeling to the 5000 most frequent words, and zero out the rest. Finally, the sequence length (number of words) in each review varies, so we will constrain each review to be 500 words, truncating long reviews and pad the shorter reviews with zero values.
Now that we have defined our problem and how the data will be prepared and modeled, we are ready to develop an LSTM model to classify the sentiment of movie reviews.
Data:-
The problem that we will use to demonstrate sequence learning in this tutorial is the IMDB movie review sentiment classification problem. Each movie review is a variable sequence of words and the sentiment of each movie review must be classified.
Step 1:-
Let’s start off by importing the classes and functions required for this model and initializing the random number generator to a constant value to ensure we can easily reproduce the results.
Step 2:-
We need to load the IMDB dataset. We are constraining the dataset to the top 5,000 words. We also split the dataset into train (50%) and test (50%) sets.
Step 3:-
Next, we need to truncate and pad the input sequences so that they are all the same length for modeling. The model will learn the zero values carry no information so indeed the sequences are not the same length in terms of content, but same length vectors is required to perform the computation in Keras.
Step 4:-
We can now define, compile and fit our LSTM model.
The first layer is the Embedded layer that uses 32 length vectors to represent each word. The next layer is the LSTM layer with 100 memory units (smart neurons). Finally, because this is a classification problem we use a Dense output layer with a single neuron and a sigmoid activation function to make 0 or 1 predictions for the two classes (good and bad) in the problem.
Keras provides this capability with parameters on the LSTM layer, dropout can be applied to the input and recurrent connections of the memory units with the LSTM precisely and separately and the dropout for configuring the input dropout and recurrent_dropout for configuring the recurrent dropout.
Because it is a binary classification problem, log loss is used as the loss function (binary_crossentropy in Keras). The efficient ADAM optimization algorithm is used.A large batch size of 64 reviews is used to space out weight updates.
Step 5:-
Once fit, we estimate the performance of the model on unseen reviews.
Training accuracy of 89.32 % was achieved and loss is 0.2687.
Testing accuracy is 86.63%.
Summary:
We learned,
1) How to develop a simple single layer LSTM model for the IMDB movie review sentiment classification problem.
2) How to extend your LSTM model with layer-wise and LSTM-specific dropout to reduce overfitting. (adding dropouts)
import numpy
from keras.datasets import imdb
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers.embeddings import Embedding
from keras.preprocessing import sequence
numpy.random.seed(7)
top_words = 5000
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=top_words)
max_review_length = 500
X_train = sequence.pad_sequences(X_train, maxlen=max_review_length)
X_test = sequence.pad_sequences(X_test, maxlen=max_review_length)
embedding_vecor_length = 32
model = Sequential()
model.add(Embedding(top_words, embedding_vecor_length, input_length=max_review_length))
model.add(LSTM(100, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(1, activation="sigmoid"))
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])
print("Model Fitting:-","\n");print("")
model.fit(X_train, y_train, epochs=3, batch_size=64)
scores = model.evaluate(X_test, y_test, verbose=0)
print("Testing Accuracy: %.2f%%" % (scores[1]*100))
Leave a Reply