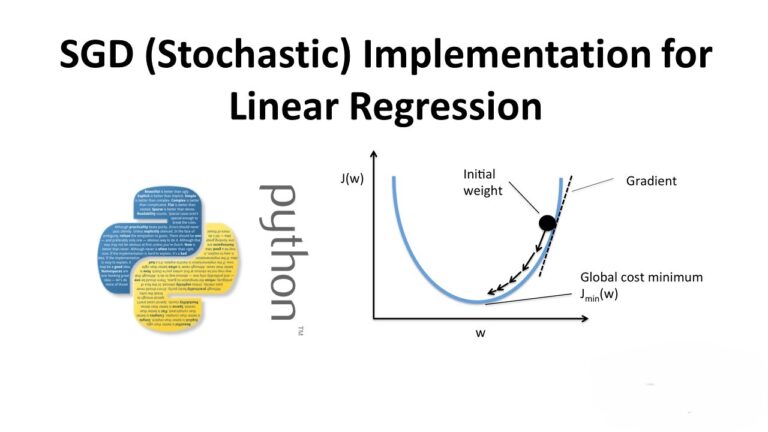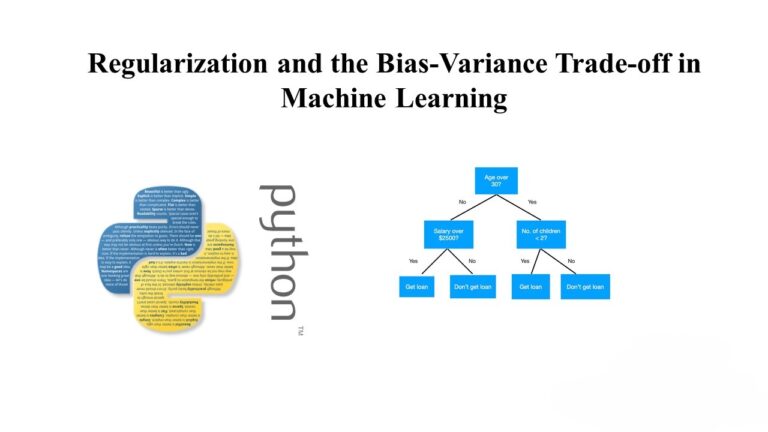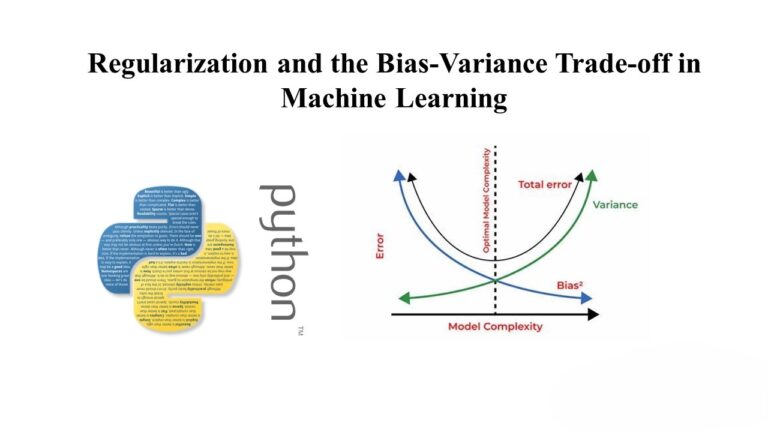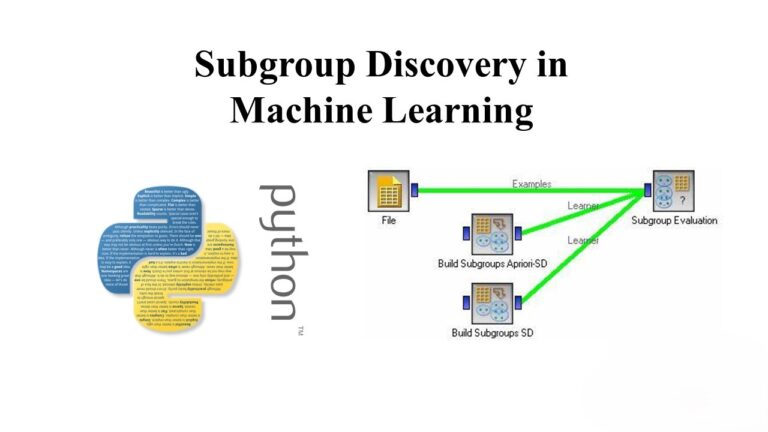
A Guide to Subgroup Discovery in Machine Learning
In the vast landscape of machine learning, uncovering hidden patterns in data is often the key to unlocking valuable insights. One powerful technique for achieving this is subgroup discovery, a method that focuses on identifying subsets of data that exhibit unique or interesting behavior. In this blog post, we’ll explore the concept of subgroup discovery…