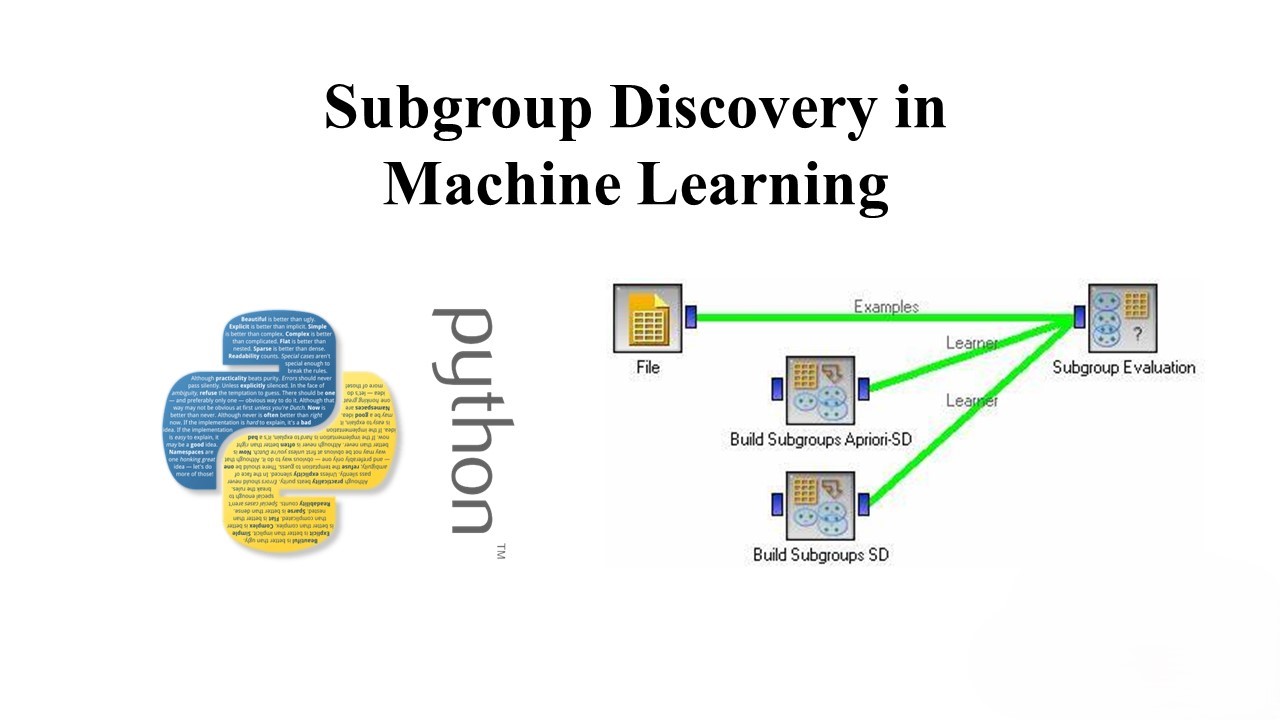
A Guide to Subgroup Discovery in Machine Learning
In the vast landscape of machine learning, uncovering hidden patterns in data is often the key to unlocking valuable insights. One powerful technique for achieving this is subgroup discovery, a method that focuses on identifying subsets of data that exhibit unique or interesting behavior. In this blog post, we’ll explore the concept of subgroup discovery and walk through a Python implementation of this technique using the popular scikit-learn library.
Understanding Subgroup Discovery
Subgroup discovery is all about finding subsets of data that are statistically significant with respect to a particular target variable. These subsets, or subgroups, are characterized by a combination of attribute values that distinguish them from the rest of the data. By identifying these subgroups, we can gain a deeper understanding of the underlying patterns in the data and make more informed decisions.
Implementing Subgroup Discovery in Python
To demonstrate how subgroup discovery works, let’s consider a hypothetical dataset containing information about customers and their purchasing behavior. Our goal is to identify subgroups of customers who are more likely to make a purchase. We’ll use the scikit-learn library to perform subgroup discovery.
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import pandas as pd
# Load the dataset
data = pd.read_csv('customer_data.csv')
# Split the data into features and target variable
X = data.drop('purchased', axis=1)
y = data['purchased']
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Fit a decision tree classifier to the training data
clf = DecisionTreeClassifier(random_state=42)
clf.fit(X_train, y_train)
# Make predictions on the test data
y_pred = clf.predict(X_test)
# Calculate the accuracy of the model
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy:', accuracy)In this example, we load the customer data, split it into features and the target variable (whether a customer made a purchase), and then split it into training and test sets. We then fit a decision tree classifier to the training data and use it to make predictions on the test data. Finally, we calculate the accuracy of the model.
Conclusion
Subgroup discovery is a powerful technique for uncovering hidden patterns in data. By identifying subsets of data that exhibit unique behavior, we can gain valuable insights that can inform decision-making and drive business success. The Python implementation provided in this blog post serves as a basic introduction to the concept of subgroup discovery and can be expanded upon to tackle more complex datasets and problems.