The Mathematics Behind Machine Learning
Machine learning is a branch of artificial intelligence that enables computers to learn from data and make decisions or predictions without being explicitly programmed. At the core of machine learning algorithms lie mathematical concepts and principles that drive their functionality. In this blog post, we’ll explore some key mathematical concepts behind machine learning.
Linear Algebra
Linear algebra plays a fundamental role in machine learning, particularly in the representation and manipulation of data. Some key concepts include:
- Vectors and Matrices: Vectors represent arrays of numbers, while matrices are 2D arrays. They are used to represent features and data points in machine learning.
- Matrix Operations: Operations such as addition, multiplication, and inversion are used extensively in machine learning algorithms like linear regression and neural networks.
- Eigenvalues and Eigenvectors: These concepts are used in dimensionality reduction techniques like Principal Component Analysis (PCA).
Calculus
Calculus is essential for understanding the optimization algorithms used in machine learning. Some key concepts include:
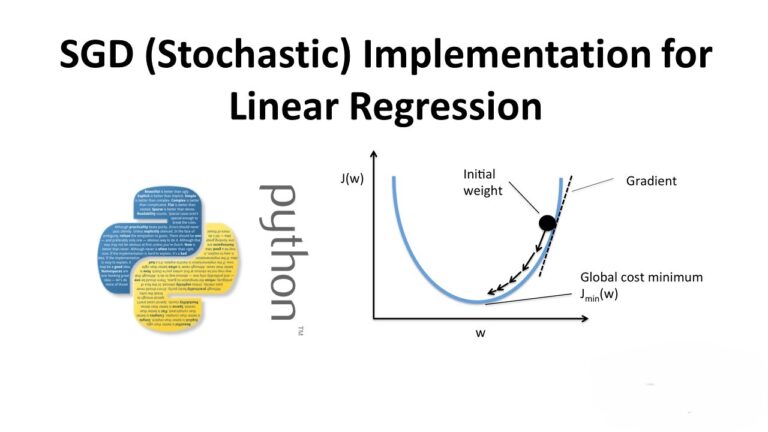
- Derivatives: Derivatives are used to find the rate of change of a function, which is crucial in gradient descent optimization.
- Gradient Descent: This optimization algorithm uses derivatives to find the minimum of a function, which is used to minimize the error in machine learning models.
Probability and Statistics
Probability and statistics are core to understanding uncertainty and making predictions in machine learning. Some key concepts include:
- Probability Distributions: Understanding distributions like Gaussian (normal) distribution is crucial for modeling data and making predictions.
- Bayesian Inference: This statistical method is used to update beliefs about a hypothesis as new evidence or data becomes available.
- Hypothesis Testing: This is used to evaluate the significance of results obtained from experiments or models.
Information Theory
Information theory provides a framework for measuring information and entropy in data. Some key concepts include:
- Entropy: This measures the uncertainty or randomness in a dataset, which is used in decision tree algorithms.
- Kullback-Leibler Divergence: This measures how one probability distribution diverges from a second, expected probability distribution and is used in model evaluation.
Conclusion
Mathematics forms the foundation of machine learning, enabling us to build complex models, analyze data, and make informed decisions. Understanding these mathematical concepts is crucial for anyone aspiring to work in the field of machine learning.