A Visual Guide To Sampling Techniques in Machine Learning
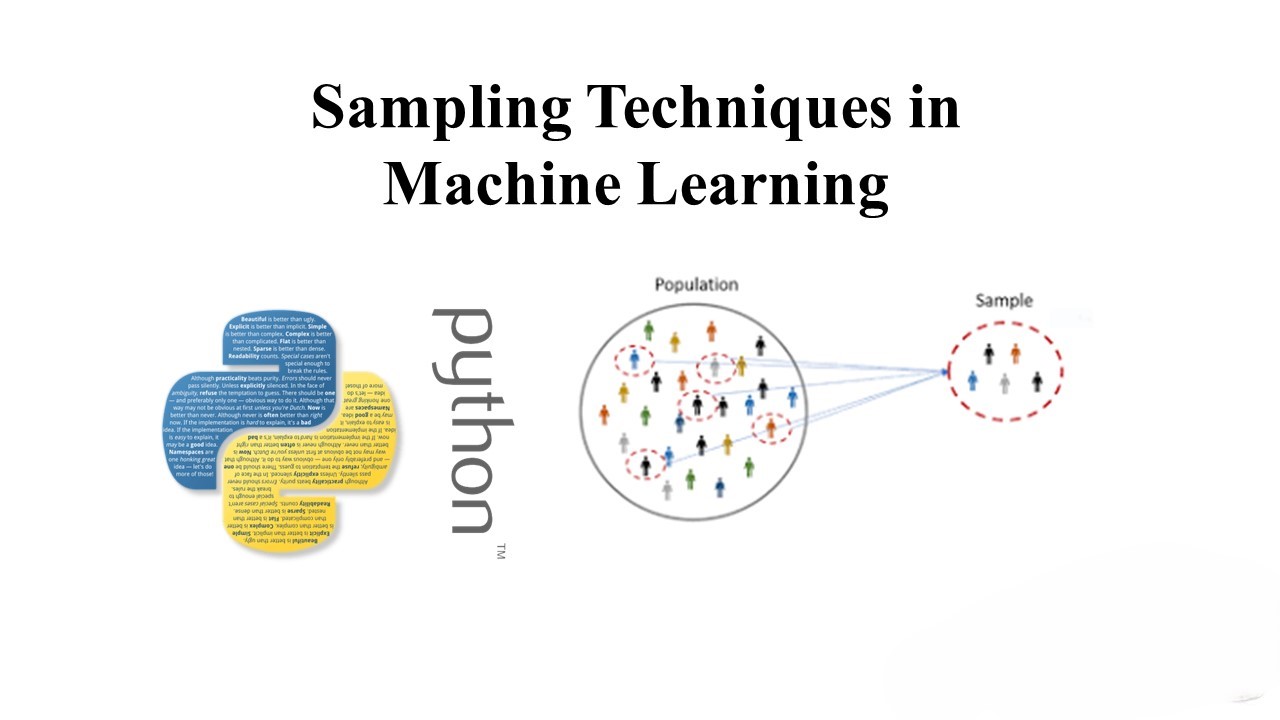
When working with large datasets, it’s often impractical to train machine learning models on the entire dataset. Instead, we opt to work with smaller, representative samples. However, the way we sample can significantly impact the performance and accuracy of our models.
Let’s explore some commonly used sampling techniques:
🔹 Simple Random Sampling: Each data point has an equal chance of being selected, ensuring a truly random sample.
🔹 Cluster Sampling (Single-Stage): Divide the dataset into clusters and randomly select entire clusters for sampling.
🔹 Cluster Sampling (Two-Stage): Similar to single-stage cluster sampling, but instead of selecting entire clusters, we randomly select data points within selected clusters.
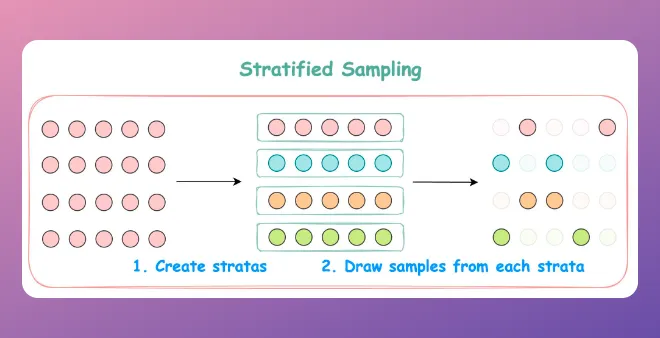
🔹 Stratified Sampling: Divide the dataset into distinct strata or groups (e.g., based on age or gender), and then randomly sample from each stratum.
Sampling is not just about randomly selecting data points; it’s about ensuring that our sample is representative of the entire population. This is crucial for building robust and accurate machine learning models.
Implementing Simple Random Sampling in Python:
import pandas as pd
import numpy as np
# Sample dataset
data = pd.DataFrame({'A': range(1, 101), 'B': np.random.randn(100)})
# Simple random sampling
sample = data.sample(n=10, random_state=42)
print(sample)Implementing Stratified Sampling in Python:
from sklearn.model_selection import train_test_split
# Sample dataset
data = pd.DataFrame({'A': range(1, 101), 'B': np.random.randn(100), 'Category': np.random.choice(['X', 'Y'], 100)})
# Stratified sampling
train, test = train_test_split(data, test_size=0.2, stratify=data['Category'], random_state=42)
print(train)
print(test)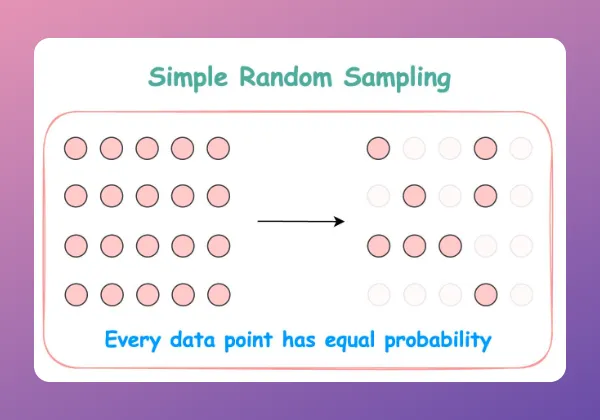
What are some other sampling techniques that you commonly use? Share your thoughts in the comments below!